Dubletten und Unikate
Zwei Datensätze in einer Datenbank gehören entweder zu einer oder zu zwei unterschiedlichen Personen. Im ersten Falls ist es eine Dublette, im zweiten sind es zwei Unikate. Dubletten finden ist eine anspruchsvolle Aufgabe. Dazu werden ausgeklügelte Programme entwickelt. Sie arbeiten mit Algorithmen, die Ähnlichkeiten der Daten berücksichtigen. Diese Programme sind jedoch nicht immer in der Lage, automatisch zu entscheiden, ob es sich um eine Dublette oder Unikate handelt. Deshalb machen wir beim Einsatz von Software für die Erkennung von Dubletten die Einteilung in sichere und mögliche Dubletten.
Sichere Dubletten
Sichere Dubletten sind Datensätze, die sehr ähnlich sind. Sie stimmen so weit übereinstimmen, dass sicher dieselbe Person gemeint ist.
So gelten beispielsweise als sichere Dubletten Datensätze, bei denen
- Name
- Vorname
- Geburtsdatum
- Telefonnummer
übereinstimmen oder sich sehr ähnlich sind.
Ein weiteres Beispiel für eine sichere Dublette sind zwei Datensätze, in denen
- Name
- Vorname
- SVA-Nummer
übereinstimmen oder sich sehr ähnlich sind.
Die Wahrscheinlichkeit, hier einen Fehler zu machen, ist sehr klein.
Es ist verhältnismässig einfach, die sicheren Dubletten zu finden. Sogar, wenn berücksichtigt wird, dass Name, Vorname fehlerhaft geschrieben worden sind, oder Verwechslungen vorkommen, sind gute Algorithmen in der Lage, die sicheren Dubletten zu identifizieren.
Mögliche Dubletten
Um Grössenordnungen komplizierter als die Ermittlung der möglichen Dubletten. Bei ihnen sind die Datensätze zwar ähnlich sind. Sie stimmen aber nicht genügend gut überein, um sie als sichere Dubletten zu identifizieren.
Beispiele für solche möglichen Dubletten sind in der Tabelle aufgeführt. Dabei sind die jeweils übereinstimmenden Daten gelb hinterlegt.
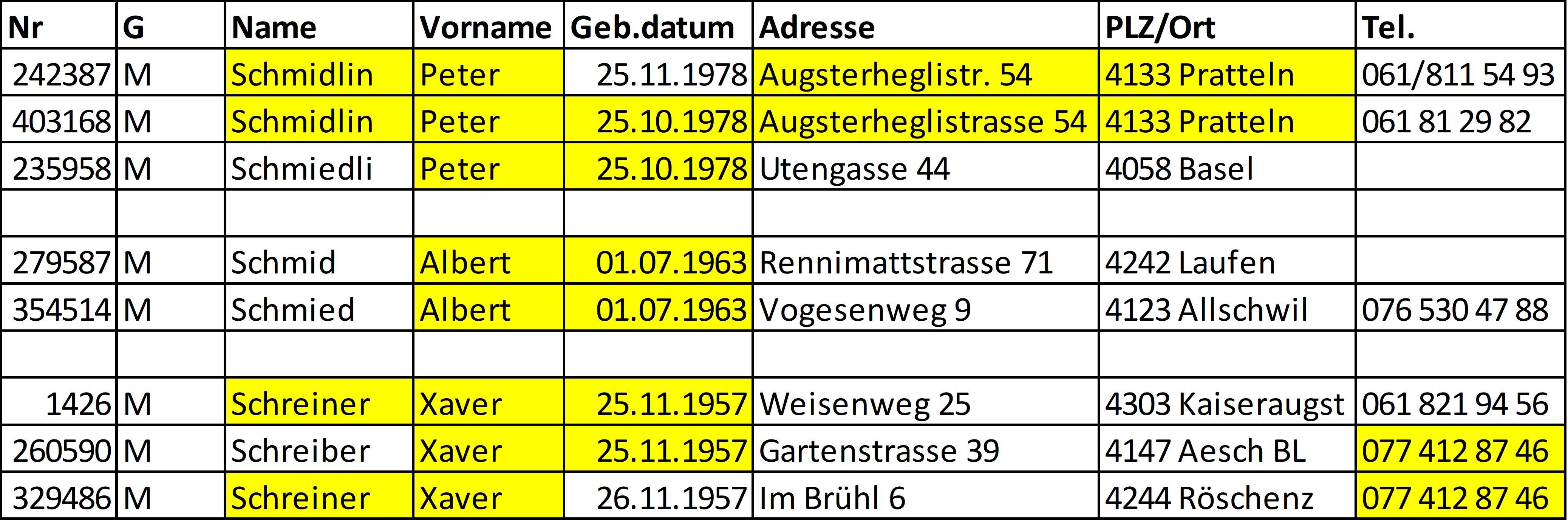
Die Frage, die sich hier stellt: Wie finde ich ähnliche Datensätze, die Dubletten sein könnten. Und wie kann ich sie sinnvoll in Gruppen zusammenfassen? Dabei kann es sich um eine Million verschiedener Datensätze handeln. Die Lösung dieser Aufgabe führt zu so genannten Verfahren der Gruppenbildung.
