Personendaten bereinigen: Was heisst dies? Wie geht das? Was treffen wir an? Wie müssen wir in einem solchen Projekt vorgehen? In diesem Beitrag möchten wir eine Struktur der Lösung vorstellen, die sich in der Praxis bewährt hat. Wir stellen dabei die Sicht der Informatik in den Vordergrund.
Personendaten bereinigen: Was treffen wir an?
In den meisten Fällen treffen wir auf folgende Lage:
- Die Ausgangssituation, was die Daten anbetrifft, ist meist unklar. Wie gut sind die Daten überhaupt? Mit welchem Aufwand müssen wir rechnen, um unsere Personendaten zu bereinigen?
- Die Soll-Situation ist oftmals ebenfalls nicht eindeutig geklärt. Fragen zur Struktur der Daten, wie auch zu deren Inhalt sind noch offen. Welche Daten brauche ich in Zukunft überhaupt noch? Benötige ich zusätzliche Daten?
Wer muss mitmachen?
Vor allem andern möchten wir auf einen Punkt hinweisen:
Die Aufgabe des Bereinigens der Daten kann nur im Team gelöst werden. Viele unterschiedliche Spezialisten müssen zusammenwirken, damit das Bereinigen der Personendaten gelingt. Die Informatiker können mit den Daten korrekt umgehen. Sie kennen jedoch den Inhalt und die Bedeutung der Daten zu wenig gut. Dazu braucht es die Verantwortlichen der Daten. Die sogenannten Data Owner entscheiden, welche Daten in der Organisation gebraucht werden. Sie können auch überflüssige Daten identifizieren. Sie verhindern damit, dass Personendaten bereinigt werden, die keinen Nutzen bringen.
Diese Gründe legen nahe, ein geordnetes Vorgehen zu wählen.
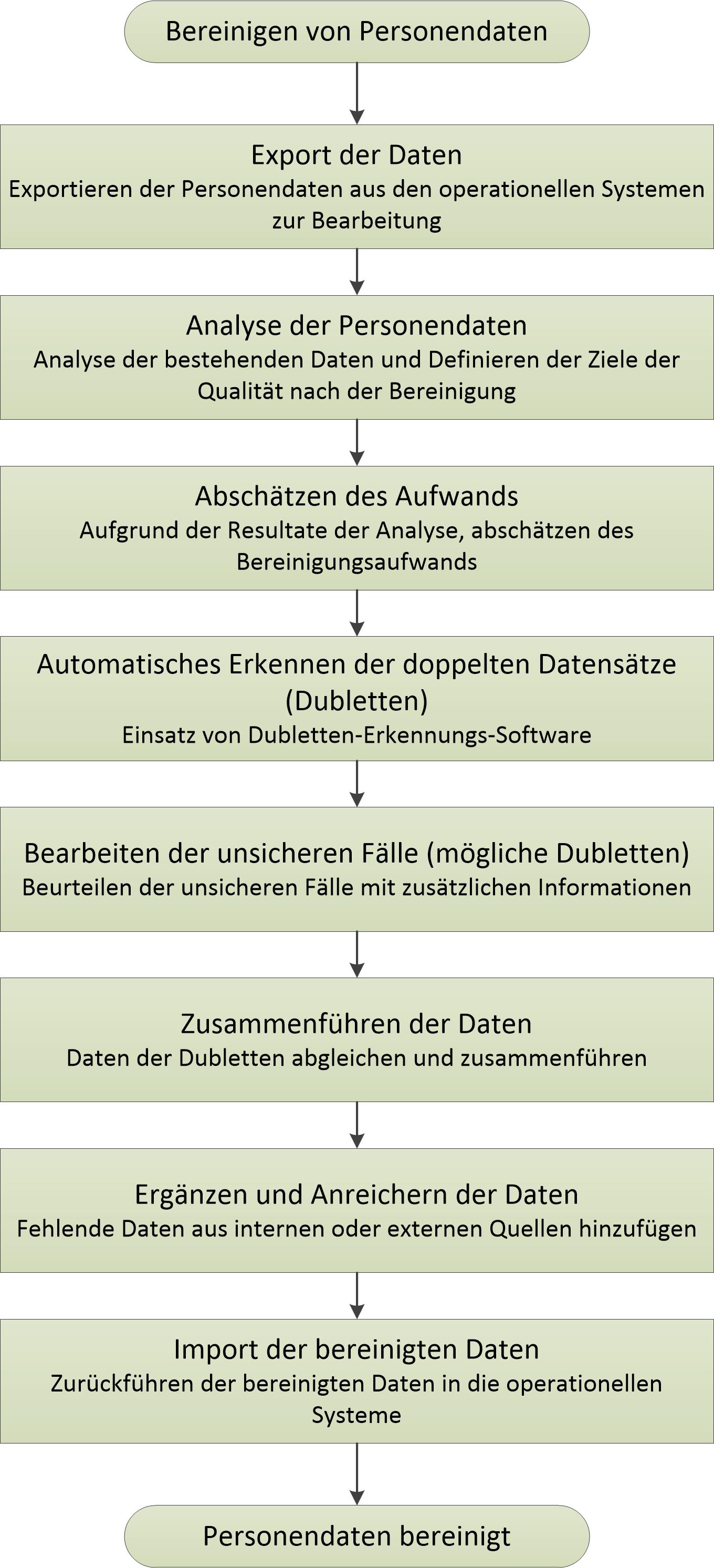
Schritte beim Bereinigen von Personendaten
In vielen Projekten haben sich folgende Schritte als sinnvoll erwiesen. Sie werden feststellen, dass es sich um ein klassisches Projektmodell handelt. Allerding legen wir die Schwerpunkte auf die Daten anstatt auf die Funktionalität.
Die Schritte sind die folgenden:
1. Export der Daten
Führen Sie alle nachfolgenden Arbeiten ausserhalb der laufenden, operationellen Systeme durch. Dazu exportieren Sie die relevanten Daten, am einfachsten in eine Excel- Datei. Hier können Sie die Daten einfach ordnen und sich schon einen Überblick über die Daten verschaffen.
2. Analyse der Personendaten
- Wenn wir die Qualität der Personendaten nicht kenn, müssen wir sie zuerst überprüfen. In einer Analyse ermitteln wir, in welchem Zustand sich die Daten befinden. Wir brauchen dazu natürlich Qualitätskriterien. Diese umfassen Vollständigkeit und Korrektheit. In Qualitätskriterien legen wir für jedes Datenfeld die Anforderungen fest.
- Die Data Owner überprüfen in dieser Phase, ob ihre Anforderungen an den Inhalt der Daten erfüllt sind. Dabei legen sie fest, welche Daten zusätzlich erhoben werden müssen (Anreicherung der Daten) und welche Daten gelöscht werden können.
- Ein spezielles Thema sind die Dubletten. Dubletten sind doppelte Datensätze, die zu derselben Person gehören. Oftmals enthalten sie unterschiedliche, manchmal widersprüchliche Informationen. Ihre Bereinigung kann aufwändig sein. Doch zuerst müssen sie erkannt werden. Vermuten Sie Dubletten in ihren Personendaten, so gehört eine Abschätzung der Anzahl Dubletten in die Analysephase.
Nun haben Sie eine Übersicht über die Aufgabe. Die Resultate kommunizieren sie allen am Projekt beteiligten und verantwortlichen Personen. Vielleicht ist es der erste Zeitpunkt, der Ihnen eine ungefähre Grösse des Vorhabens gibt. Nun ist es aber Zeit für eine genauere Abschätzung des Aufwands.
3. Abschätzen des Aufwands
Nun machen wir uns daran, den Aufwand für das Bereinigen abzuschätzen. Die Analyseresultate zeigen uns:
-
- Datenmenge, das Mengengerüst
Die Datenmenge allein genügt nicht für das Abschätzen des Aufwands zur Bereinigung. Doch macht es einen Unterschied, ob wir 10‘000, 100‘000 oder 1‘000‘000 Daten betrachten müssen. - Abweichung der Ist-Qualität von der geforderten Soll-Qualität der Daten
Nun haben wir die Differenzen zwischen der vorhandenen und der gewünschten Datenqualität festgestellt. Daten korrigieren ist jedoch keine beliebte Tätigkeit. Aber ohne Arbeit lässt sich die Qualität der Daten nicht verbessern. Selbstverständlich können einige Fehler automatisch mit Programmen oder Skripten korrigiert werden. Es sind die nicht automatisch korrigierbaren Fehler oder Datenlücken, welche den Aufwand verursachen. Und diesen müssen wir abschätzen. - Für die Abschätzung des Aufwands typisieren wir die notwendigen Korrekturen. Pro Korrekturtyp schätzen wir einen durchschnittlichen Arbeitsaufwand ab. Dann multiplizieren wir ihn mit der Anzahl Korrekturen dieses Typs. Die Summe über alle Korrekturen ergibt dann den Gesamtaufwand. Nur zu oft sorgt diese Zahl für eine Überraschung.
- Anzahl der vorhandenen Dubletten
Weshalb sind die Dubletten wichtig? Erstens führen sie zu schwerwiegenden Folgefehlern in Datenbanken. Zweitens sind sie nicht einfach zu entdecken. Und drittens verursacht ihre Korrektur viel Aufwand. Deshalb brauchen wir eine Abschätzung der Anzahl Dubletten. Zudem schätzen wir den Aufwand für das Korrigieren, d.h. das Zusammenführen einer Dublette ab. Durch Multiplikation der beiden Faktoren erhalten wir den geschätzten Aufwand zur Bereinigung der Dubletten.
- Datenmenge, das Mengengerüst
Nun haben wir alle Grundlagen, um Kosten, Zeit und Bedarf an Ressourcen herzuleiten. Die Resultate sind in einer ganz normalen Projektplanung zusammengefasst.
4. Automatisches Erkennen der Dubletten (data matching)
Wir haben jetzt die technisch anspruchsvollste Aufgabe vor uns. Dubletten sind nicht einfach Verdoppelungen eines Datensatzes. Falsch geschriebene Namen oder Vornamen, Tippfehler bei der Eingabe, Verwechslungen von Daten sind die Hauptverantwortlichen für Dubletten. Bei kleinen Datenmengen sind wir in der Lage, die Daten optisch zu überprüfen und die Dubletten zu identifizieren. Unsere Fähigkeit und Geduld für diese Arbeit gelangen jedoch rasch an ihre Grenzen. Bei grösseren und grossen Mengen von Datensätzen ist eine programmtechnische Unterstützung unerlässlich. Nur mit sehr ausgeklügelten Programmen gelingt es, die Dubletten zu erkennen. Die App ‚Dubletten – data matching‘ der CrowTen unterstützt sie bei dieser Arbeit.
5. Optisches Beurteilen und Erkennen der möglichen Dubletten
Kein Algorithmus kann alle Dubletten mit absoluter Sicherheit erkennen. Deshalb teilen ernst zu nehmende Programme die Resultate der Dublettensuche in drei Kategorien ein:
- Unikate
- Dubletten
- Mögliche Dubletten
Bei den möglichen Dubletten stimmen die Datensätze nicht genügend überein. Die Differenz liegt oberhalb der Toleranzgrenze. Diese Dubletten müssen wir speziell untersuchen. Wir beurteilen die Daten mit unserem zusätzlichen Wissen, ob es sich bei einer möglichen Dublette um eine Dublette oder um zwei Unikate handelt.
6. Zusammenführen der Informationen der Dubletten (data merging)
Jetzt kennen wir die Unikate und die Dubletten in unseren Daten. Am Schluss wollen wir nur noch Unikate haben. Deshalb fügen wir die Informationen der Dubletten in einem Datensatz zusammen. Wir definieren die Regeln für das Zusammenführen (data merging) der Daten. Diese Regeln setzen wir in Skripte um und korrigieren so die Daten. In sehr komplizierten Fällen kommen wir auch hier nicht um Handarbeit herum.
7. Anreichern und ergänzen der Daten
Wir haben die Daten in eine Form gebracht, in der sie angereichert und ergänzt werden können. Hätten wir solche Arbeiten schon früher durchgeführt, wären sie unter Umständen nutzlos gewesen. Durch das Bereinigen der Dubletten hätten wir die Änderungen vielleicht wieder überschrieben.
8. Import der bereinigten Daten
Beim Import der der bereinigten Daten unterscheiden wir verschiedene Fälle:
- Ein neues System wird aufgebaut (Datenmigration)
In diesem Fall importieren wir die bereinigten Daten in das neue System kurz vor der Inbetriebnahme - Die Daten werden in einem laufenden System bereinigt
Wir haben die Daten ausserhalb des laufenden Systems bearbeitet. Jetzt müssen wir die korrigierten Daten wieder ins System integrieren.- Kleine Menge von Korrekturen
Am einfachsten führen Sie die Korrekturen von Hand am laufenden System nach. Besondere Vorsicht müssen sie bei den Datensätzen, die gelöscht werden (überflüssige Dubletten) walten lassen. Eventuell bestehen Verknüpfungen zu anderen Daten. - Mittelgrosse Menge von Korrekturen
In diesem Fall lohnt es sich Datenbankskripte zu erstellen, welche die Korrekturen nachführen. - Grosse Anzahl von Korrekturen
Bei einer sehr grossen Anzahl von Korrekturen stossen wir auf eine zusätzliche Aufgabe: Personendaten bereinigen in Etappen.
- Kleine Menge von Korrekturen
Ablaufdiagramm Personendaten bereinigen: Wie geht das?