Zuerst eine Definition
Bevor wir uns dem Bearbeiten möglicher Dubletten zuwenden, eine kleine Definition. Was sind überhaupt mögliche Dubletten? Woher kommt dieser Begriff? Eigentlich ist es ganz einfach. Auch die besten Algorithmen können Dubletten nicht immer mit Sicherheit erkennen. Ein Beispiel dafür: Sind Peter Meier und Laurin Meier Zwillinge? Sie haben dasselbe Geburtsdatum, den 1. Februar 1977, und dieselbe Wohnadresse. Und doch könnten es auch Vater und Sohn sein. Unter Umständen ist das Geburtsdatum von Laurin nicht richtig. Deshalb darf ein guter Algorithmus zur Suche von Dubletten sie nicht einfach als Dubletten ausweisen.
Um zu verstehen, wie mögliche Dubletten entstehen, müssen wir kurz die Arbeitsweise des Algorithmus darstellen.
Ein Algorithmus zum Erkennen der Dubletten bildet Gruppen ähnlicher Datensätze. Ist die Übereinstimmung von zwei Datensätzen genügend gross, erkennt der Algorithmus sie als Dubletten. Ist die Übereinstimmung klein, so erkennte er sie als Unikate. Dazwischen jedoch bleiben Gruppen von Datensätzen, die weder eindeutig als Dubletten, noch als Unikate erkannt werden. Diese übrig bleibenden Datensätze, die unsicheren Fälle, nennen wir mögliche Dubletten. Diese müssen weiter bearbeitet werden. Spezialisten mit genügend Kenntnissen über die Daten überprüfen sie mit Hilfe zusätzlicher Informationen. Sie weisen sie nach Abklärung entweder den Unikaten oder den Dubletten zu.
Zwei Fragen stellen sich nun:
- Wie kann man herausfinden, ob eine mögliche Dublette eine Dublette ist oder zwei Unikate sind?
- Welche technischen Hilfsmittel stehen zur Verfügung, um die unsicheren Fälle effizient zu beurteilen?
Grundlagen zur Entscheidung: Unikat oder Dublette?
Mögliche Dubletten werden von Menschen aufgrund der folgenden Kriterien als Dubletten oder Unikate erkannt:
- Einige Datenfehler werden mittels Plausibilitätsüberlegungen vom Menschen sicherer beurteilt als von einem Algorithmus. Beispielsweise sind auch sehr falsch geschriebene Strasennamen für das menschliche Auge identifizierbar.
- Unstrukturierte Werte für Datenbankeinträge können vom Menschen sofort als gleichwertig erkannt werden. Solche Einträge können mit den heutigen Mitteln durch Algorithmen nicht sicher beurteilt werden. Ein Beispiel dafür sind die Berufsbezeichnungen in der untenstehenden Tabelle..

- Kontextwissen, welche die bearbeitende Person mitbringt, um die Datensätze besser zu beurteilen. Zum Beispiel weiss die Person, wie die Daten entstanden sind und kann daraus Nutzen ziehen.
- Beiziehen weiterer Quellen (z.B. Informationen aus anderen Systemen)
- Nachfrage bei externen Stellen (z.B. bei Gemeindebehörden)
Mit Hilfe dieser zusätzlichen Informationen bearbeiten die Spezialisten die möglichen Dubletten und weisen sie eindeutig den Unikaten oder sicheren Dubletten zu.
Nicht entscheidbare Fälle
Es kann vorkommen, dass trotz aller Abklärungen mögliche Dubletten übrigbleiben. Sie konnten nicht den zwei Kategorien Unikate oder Dubletten zugewiesen werden. Dann bleiben sie als zwei Unikate in der Datenbank.
Würden sie zusammengeführt, so würden im nächsten Schritt des data merging Informationen zusammengeführt, die nicht zusammengehören. Besonders kritisch ist dies bei medizinischen Informationen, wenn zu einem Patienten Daten eines anderen Patienten zuordnet würden.
Bearbeiten der möglichen Dubletten
Welche technischen Hilfsmittel stehen zur Verfügung?
Mit technischen Hilfsmitteln lassen sich die möglichen Dubletten effizienter beurteilen. Um brauchbar zu sein, müssen die Hilfsmittel die folgenden Eigenschaften aufweisen:
- Übersichtliche Darstellung der Gruppen der möglichen Dubletten
- Darstellung aller zur Verfügung stehenden Informationen zu den möglichen Dubletten
- Einfache Eingabe der Entscheidung: Unikat oder Dublette
- Möglichkeit der Aufteilung der Datensätze zur Parallelbearbeitung durch mehrere Personen.
Als Beispiel eines Softwaretools zur Bearbeitung der möglichen Dubletten ist die Oberfläche des Data AppKit Bearbeitungstools der CrowTen abgebildet.
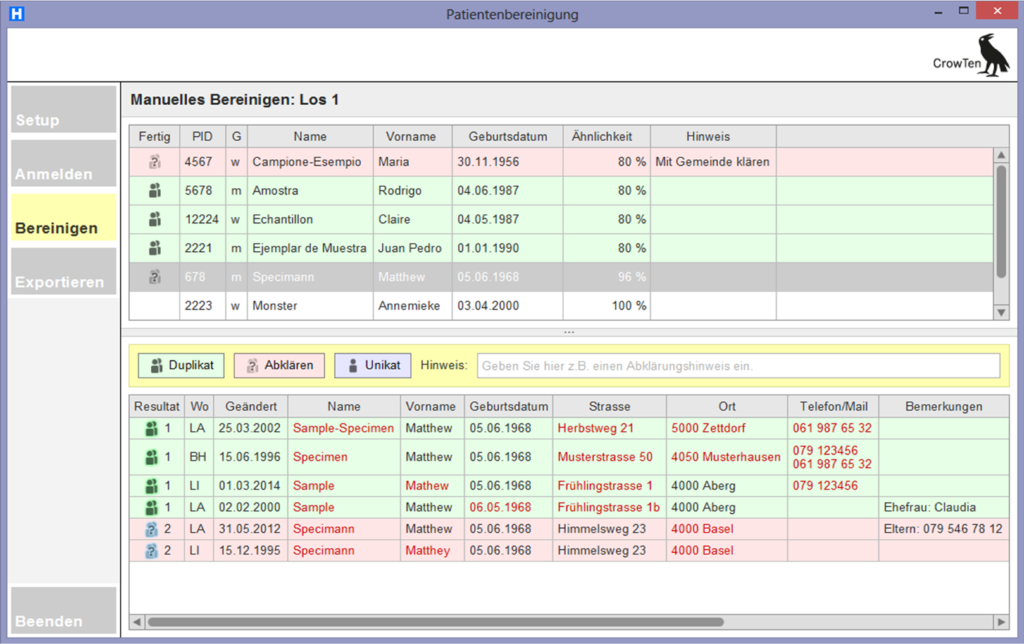
In der oberen Bildschirmhälfte sind die Gruppen aufgelistet. Die Zeile der angewählten Gruppe ist grau hinterlegt. Alle dazu gehörenden Datensätze erscheinen dann in der unteren Bildschirmhälfte. Für jeden einzelnen Datensatz kann dann der Bearbeiter seinen Entscheid Dubletten oder Unikat eintragen.
